The Data Model
S2Graph uses the property graph model[1] which represents a graph with vertices (nodes), edges (relationships), and their properties. The image below is an example where the friendships and the activities in a social media are constructed as a graph.
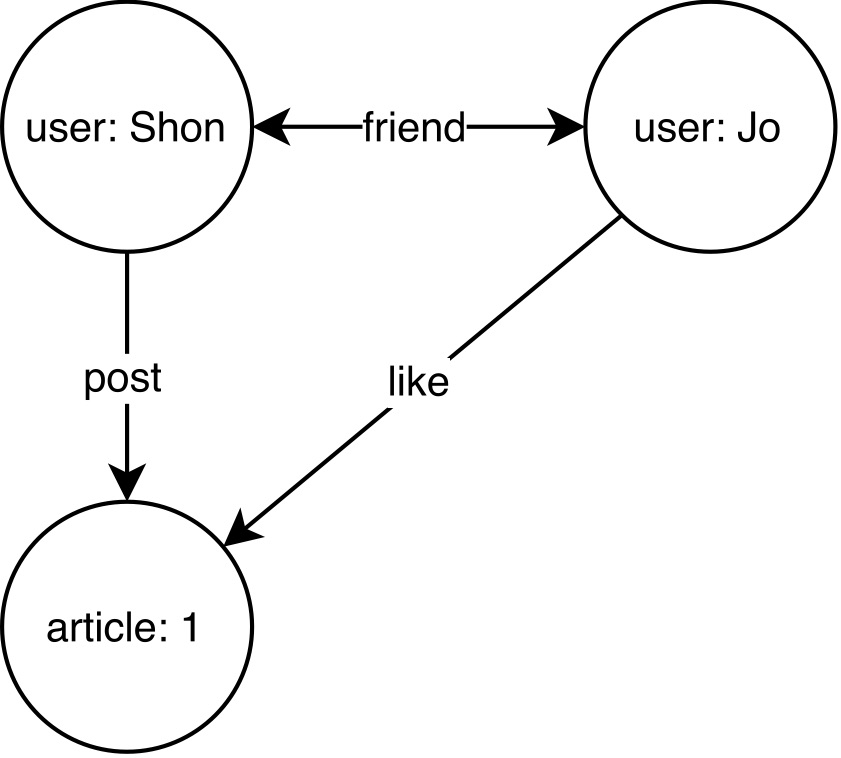
In this image, users and articles correspond to the vertices, and the connections between them, i.e. friend, post, and like, are the edges. The properties of the edges and the vertices can contain additional information regarding the relationships and the nodes.
The following four are the key abstractions that summarize S2Graph's data model:
A service refers to the top level abstraction providing a convenient logical grouping of related entities, similar to the database abstraction that most relational and document databases support. At Kakao, a service usually represents one of the company's actual services and is named accordingly, e.g. Kakao Talk (instant messenger), Kakao Story (social media), and Kakao Music (music streaming).
A column is a set of homogeneous vertices such as users, news articles or tags. Every vertex contains a user-provided unique ID for efficient look-ups. A service typically consists of multiple columns; for example, service Kakao Music may have columns users and tracks.
A label is a collection of homogeneous edges, e.g. friendships, views, or clicks. It can represent a certain relation between two columns or a recursive association within one column. For instance, an edge in like label may denote "a user likes this post", while another edge in friend label can mean that "there's a friendship between this user and another user". The two columns of a label, which the edges are connecting to and from, do not necessarily have to be in the same service. This allows us to store and query data that span over many services. For example, a single S2Graph query can return a ranking that combine Kakao Music users' activities with either their closest friends in Kakao Talk or corresponding Kakao Story users' activities. We do not assign unique IDs to the edges, but instead we can identify them by its source and target vertices.
Properties refer to the key-value data included in each vertex or edge. The names and types of properties need to be specified during the schema creation of a column or a label. In a label schema, we can optionally set one or more properties as indexed, which allows both the fast look-ups using the key-value pair and the queries for retrieving a list of edges or vertices sorted according to one of the properties. A property, for example, can be the birthday of a user or the similarity scores between music tracks. In case of representing a mathematical graph as in the standard graph theory, edge weights can be encoded as property values as well.
Using the abstractions described above, a unique edge can be identified with its (service, label, source vertex id, target vertex id), while a unique vertex can be identified with its (service, column, vertex id).
Additional information on edges and vertices are then stored within their properties.
[1] Robinson, I., Webber, J., & Eifrem, E. (2015). Graph Databases: New Opportunities for Connected Data. O'Reilly Media, Inc.
[2] Miller, J. J. (2013). Graph database applications and concepts with Neo4j. In Proceedings of the Southern Association for Information Systems Conference, Atlanta, GA, USA.