The Low-Level Data Formats
This document describes the low-level data structures that make efficient graph queries possible. Understanding this is not necessary for using S2Graph, and first-time readers are encouraged to skip to the REST API Glossary.
S2Graph's data model is backed by three, cleverly designed internal data formats: index edges, snapshot edge, and vertices.
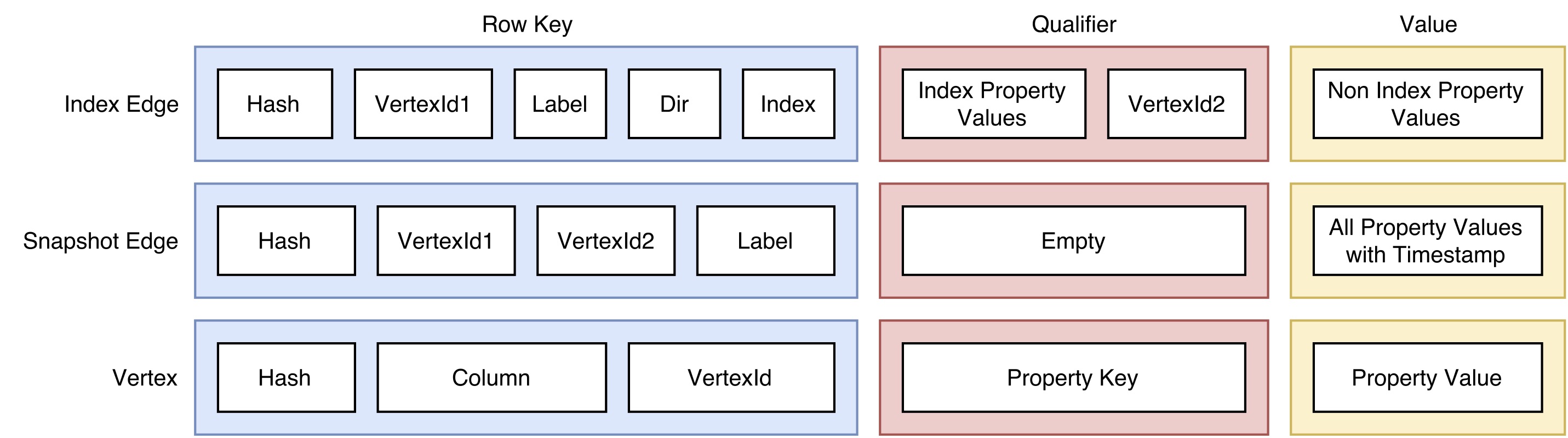
Index Edge
All edges that S2Graph stores are indexed by one or more properties, to support efficient calculation of top-k items. This format is an essential component of S2Graph since the information required to serve ranking results is stored as index edges.
Row Key
The row key structure of an Index Edge contains a hashed value of the source vertex ID, the source vertex ID itself, label name, direction, and index information.
- Source vertex ID hash: In HBase, starting the row key with a hash value is a common practice to avoid hot region problems.
- Direction: S2Graph supports directional querying. (think of friends on my Favorites list vs friends that have me as their Favorites.) This is achieved by keeping the direction in the row key and managing mutations in in-out pairs.
- Index information: Labels can be managed with multiple indices, and each index will have separate row keys assigned. This also means that there will be duplicate data. Thus be careful with setting up indices.
Qualifier
Index Edge qualifiers contain values of index properties and target vertex IDs. This way, HBase will be able to filter query results by the indexed property.
Value
All values of properties that are not indexed are written as values of a cell. The system will be able to retrieve this information and return it to the user at query time.
Snapshot Edge
Imagine deleting an Index Edge record given only the source and target vertices with a label information (as is the case with /graphs/edges/delete API spec). Limited to the Index Edge schema, you will have to scan through all the columns in a row in order to access the desired cell, which is not very efficient. This is where Snapshot Edge comes in. Snapshot Edge is indexed by the three values above-mentioned, so that the system can look up all necessary information to randomly access a cell in the Index Edge.
Row Key
The row key structure of a Snapshot Edge contains a hashed value of the source vertex ID, the source vertex ID it self, the target vertex ID, and the Label.
Qualifier
Qualifiers are not used in Snapshot Edge representations.
Value
Snapshot Edge values are all property values of the given edge with timestamp information.
Vertex
S2Graph is a edge-focused graph database, therefore, support for vertices is currently limited to key-value look-up with vertex ID information as the key and property as the value. This results in a relatively simple schema.
Row Key
In the Vertex schema design, a row key includes vertex ID hash, vertex ID itself, and Service Column information.
Qualifier
Vertex property keys are used as qualifiers.
Value
Vertex property values are used as values.